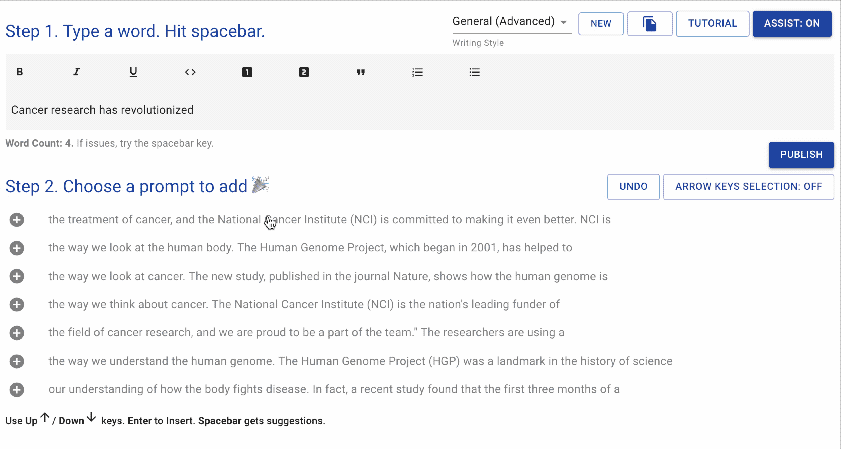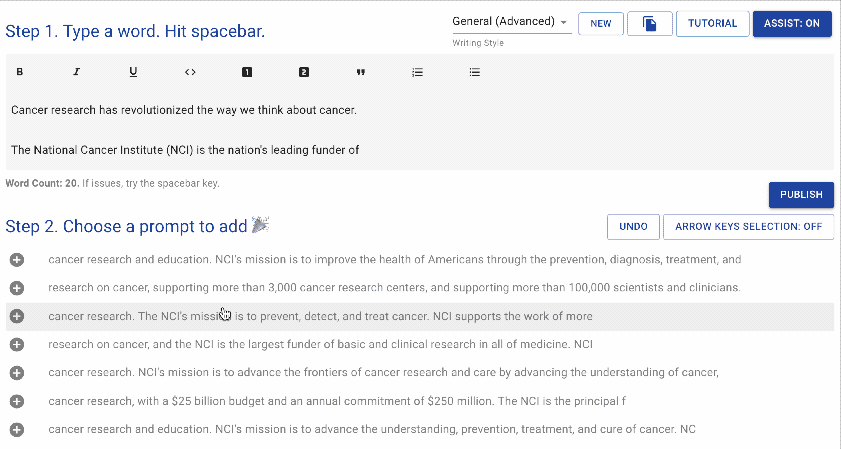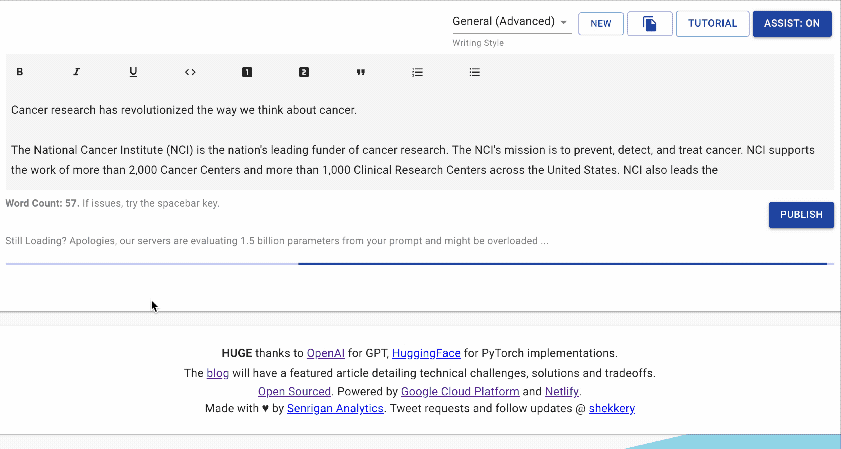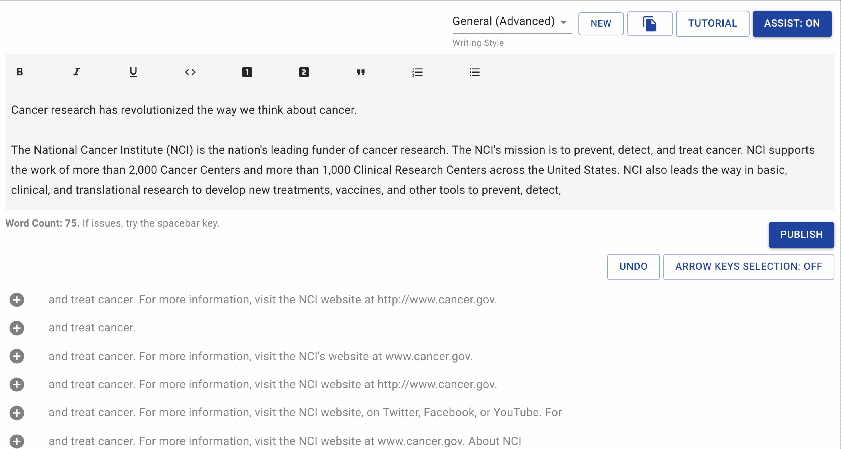
writeup.ai 是一款用于自动写作的开源文本机器人,主要基于OpenAI的GPT-2,同时搭配以下一系列经过调优的模型:
- 法律法规
- 文案与声明
- 歌词
- 哈利·波特
- 权力的游戏
- 学术研究摘要
这一次,我们的主要目标是构建一套能够快速交付OpenAI GPT-2 Medium(一套用于生成文本的机器学习模型),并同时支持10到20款面向重度用户的应用程序。
目标概述:
- 尝试在NLP(自然语言处理)场景中训练机器学习模型。我借此掌握了大量关于模型部署的知识。
- 我最初预计整个周期大概为一个月,但最终总计投入三个月时间。
- 工程难度不易估算——特别是对我这种过度自信的白痴来说~
- 遗憾的是,我对模型训练了解得不多,所以估算自然更加困难。
- 需要使用大量开源训练脚本(nsheppard)。我发现gwern的GPT2指南特别适用于本篇文章中的场景。另外,我还想向大家推荐Max的gpt-2-simple repo,也是份很棒的快速入门资料。
- Wrieup.ai大体开源,我也添加了相关链接以进一步解释自己的尝试中经历的错误/失败。另外,我也添加了指向GitHub的代码链接。
链接:
- App: writeup.ai
- Frontend Repo,GitHub
- Backend Repo,GitHub
背景介绍:
- 我个人曾拥有多年的React、Django以及Flask Web应用开发经历。
- 我在机器学习以及MLOps(机器学习DevOps)方面是个纯新手,因此请大家以平和的心态看待我的这段旅程~
读者敬启:
- 你需要拥有一定的Web开发背景积累,我也会在文章中主动提供链接以帮助大家理解相关术语。
- 最好能掌握一些机器学习方面的基础知识。
备注:
- 这里我会尽可能简明扼要地进行表述。
- 文章内会先给出全称,之后使用缩写,例如机器学习(ML)->ML。
- 在大多数情况下,这里的模型是指机器学习模型,因此不再写成“ML模型”的形式。
- 供应链锁定确实是个问题。我非常喜欢Google Cloud Platform(GCP),也完全不打算改旗易帜,因此本文中的某些建议也以使用GCP为前提。
- 根据以往使用AWS的体验来看,GCP上的ML资源部署与扩展体验都要好一些。
- 欢迎大家通过邮件、推文以及评论等方式与我交流。
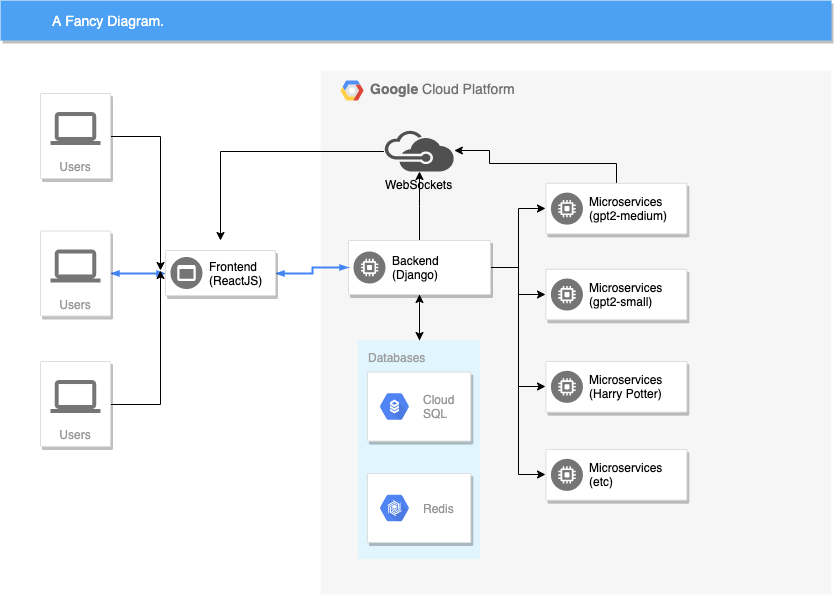
技术架构:
| 前端 | 后端 | 微服务 | |
|---|---|---|---|
| 语言 | Javascript (ES6) | Python 3.6 | Python 3.6 |
| Web框架 | ReactJS | Django (2.2) / Django-Rest-Framework | Stripped Django (2.2) / Django-Rest-Framework |
| 托管平台 | Netlify | GCP | GCP |
| 部署流程 | Netlify会根据push自动build。 | startup-scripts / Ansible | startup-scripts / Ansible |
| 创建工具 | create-react-app | cookiecutter-django | cookiecutter-django |
| 设计 | Material UI | 无;使用REST / WebSockets | 无;使用REST / WebSockets |
| 重要误国 | slatejs – 文本编辑器 | Django Channels创建WebSockets | PyTorch, TensorFlow, pytorch-transformers |
- 前端(ReactJS)加入后端(Django)中的WebSocket,并通过WebSocket实现与后端的通信。 前端代码 | 后端代码
- 后端对前端请求进行解析与序列化,并将消息(文本、算法、设置等)打包并通过WebSocket通道发送至Google Load Balancer。 后端代码
- 负载均衡器中继至适当的微服务(small、medium、large、哈利·波特、法律法规等)。
- 微服务会定期使用建议的词汇对Websocket进行实时更新,从而产生“流”效果。
- 前端从微服务处接收更新后的WebSocket消息。
- 各个ML模型(small、medium、large、哈利·波特、法律法规、学术研究等)都属于独立的微服务,并根据使用情况进行自动规模伸缩。
- 我尝试了无数次迭代以提高速度水平。
- 一般来讲,我不太喜欢微服务架构(因为会增加额外的复杂性)。但必须承认,虽然为此付出了大量精力,但微服务架构确实在性能提升方面发挥着不可替代的作用。
- 微服务的请求与计算成本,同传统的后端服务器存在巨大差别。传统的Web服务器能够轻松实现每秒500至5000条请求;但在运行1gb模型的实例当中,每秒50项请求(每项生成50到100个单词)的负载就足以让设备崩溃。(*)
- 后端与微服务采用Python 3.6编写,并使用Django(DRF)支持后端。在微服务架构中,我使用不同的Django版本支持各独立实例。
- 所有微服务实例均附带有GPU或者Cascade Lake CPU用以运行ML模型。后文将具体阐述。
- 后端与微服务托管在Google Cloud Platform之上。
- Google Load Balancer负责将所有流量路由至微服务。该负载均衡器基于“/gpt2-medium, /gtp2-medium-hp”等URL后缀,同时亦可运行健康状态检查以识别CUDA崩溃问题。
(*) - 最简单的判断方法:如果你需要刻意证明自己的用例适合微服务架构,则往往代表其没必要使用微服务方法。